
I recently finished a project I’ve been curious about for much of my AI Journey: testing whether different approaches to knowledge engineering actually improve GitHub Copilot’s effectiveness with Business Central development. The results were more revealing than I expected.
Like many of you, I’ve been wondering whether the time spent curating knowledge for AI tools actually pays off. Everyone talks about “feeding knowledge to AI,” but I hadn’t seen much systematic testing of whether it works – and more importantly, which approaches work better than others.
So I built a controlled experiment to find out. I was hoping for, but not prepared for the results:
Understanding the Knowledge Engineering Challenge
If you’ve only used GitHub Copilot in “Ask mode” – where you type questions and get answers – this might not be immediately obvious. But there’s a much bigger opportunity in how AI assistants work during actual coding.
The Problem We’re Trying to Solve
When you’re writing code, GitHub Copilot is constantly making suggestions based on what it “knows” about your technology domain. But where does that knowledge come from, and how much does it matter?
Most developers experience this as Copilot sometimes giving great suggestions and sometimes suggesting things that don’t quite fit their specific technology stack. The question is: can we systematically improve the quality of those suggestions?
And when you begin to have Copilots build things for you agentically? Whoo boy, how do you know it’s using any practices, nevermind “best practices”?
Key Concepts You Need to Know
Models vs Instructions: GitHub Copilot has a base model trained on millions of code examples, but it can also work with additional context you provide. Think of the base model as general programming knowledge, while additional context is like having a specialist consultant available.
Knowledge Context: This additional context can come from several sources:
- Files in your workspace that Copilot can reference
- Documentation you provide in
.copilot/folders - Real-time knowledge delivery through systems like Model Context Protocol (MCP)
- Community knowledge from documentation and forums
The Business Central Challenge: Business Central AL development has very specific patterns that work well (like using CalcSums for database aggregation) and patterns that work poorly (like manual loops through large datasets). Generic programming advice often misses these domain-specific optimizations.
Performance Optimization as a Test Case: I chose performance optimization as the testing ground because improvements are measurable. Either code runs faster or it doesn’t – there’s no subjective interpretation needed.
The Knowledge Engineering Hypothesis
My hypothesis was that more specific, better-structured knowledge would lead to better AI suggestions. But I wanted to test several approaches:
- Generic Programming Knowledge: Would general optimization principles help?
- Community Documentation: Would standard Business Central documentation work?
- Atomic Knowledge Engineering: Would highly specific, focused knowledge topics work better?
- Systematic Delivery: Would intelligent, real-time knowledge delivery outperform static files?
The goal was to find out which approach actually improves AI assistance quality, and by how much.
The Testing Framework I Put Together
I wanted to test this properly, so I built what I called “KnowledgeTester” – a comprehensive five-tier testing protocol designed to measure GitHub Copilot’s effectiveness across different knowledge contexts with scientific rigor.
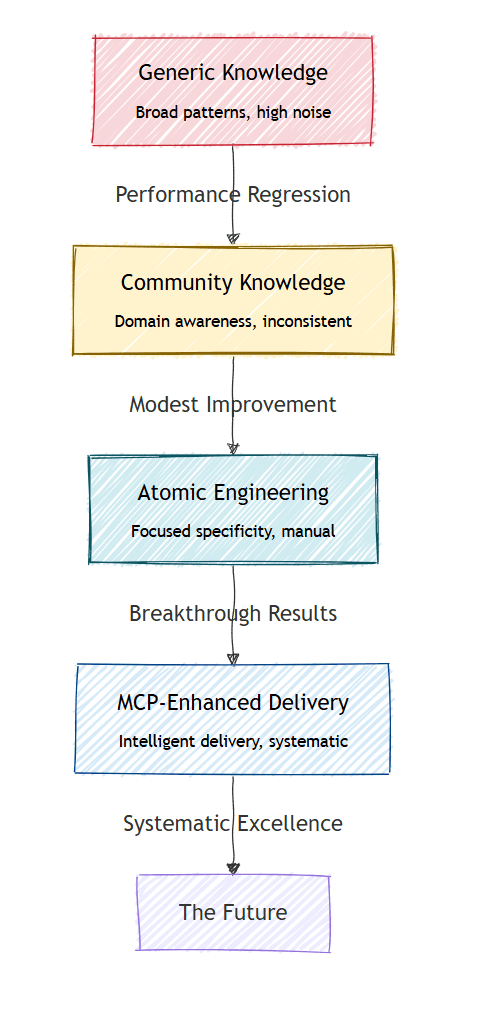
The Scientific Approach: Five-Tier Testing Framework
Unlike informal “before and after” comparisons, this framework created controlled conditions that could isolate the impact of knowledge engineering approaches:
⚫ Tier 0: Performance Baseline – Unoptimized inefficient code with no knowledge context. This established concrete “before” metrics for measuring improvements.
🔴 Tier 1: Generic Programming Knowledge – Standard programming optimization principles only. This tested whether general coding advice helps Business Central development.
🟡 Tier 2: Community BC Knowledge – General Business Central documentation and AL Guidelines from community sources. This represented what most developers have access to.
🟢 Tier 3: Atomic BC Knowledge – Focused atomic Business Central performance topics (45-60 specific patterns). This was the key hypothesis – does atomic knowledge engineering pay off?
🔵 Tier 4: MCP-Enhanced Knowledge – Model Context Protocol with intelligent, real-time Business Central knowledge delivery. This tested advanced knowledge delivery versus static approaches.
Realistic Enterprise-Scale Testing Environment
Rather than toy examples, I built a complete commercial property management system that could stress-test optimization decisions at enterprise scale:
Business Context:
- 5,000 Rental Units across 50 commercial buildings
- 3,000,000+ Transaction Records (5 years of monthly rental data)
- 22 Business Objects per tier (110 total objects across all tiers)
- 9 Functional Modules: Analytics, Compliance, Finance, Leasing, Operations, Quality, Security, Services, Vendor
Technical Architecture:
Each tier had identical codebases with the same inefficient patterns, but different ID ranges (50100-50199 for Tier 0, 50200-50299 for Tier 1, etc.). Multi-app VSCode workspaces gave GitHub Copilot access to both table structures and business logic – testing the complete spectrum of Business Central optimizations.
The Critical “Separation Trick”:
Here’s where it gets interesting – I deliberately separated the business logic from the underlying data structures, just like real Business Central development. The inefficient codeunits were in tier-specific extensions, but the table definitions, SIFT keys, and FlowFields were in a shared Common-Data-Infrastructure extension.
This meant that to properly optimize the business logic, GitHub Copilot had to follow the thread from the inefficient code back to the data model and understand how optimizing SIFT keys or adding FlowFields in the data layer could dramatically improve the application layer performance. This mirrors how Business Central development actually works – you can’t optimize business logic without understanding and potentially modifying the underlying table structures, indexes, and aggregation patterns.
Comprehensive Performance Challenge Design
Instead of simple examples, I created graduated difficulty levels that would reveal the sophistication of each tier’s optimization capabilities:
🟢 Easy Wins (4 procedures per tier) – Basic programming improvements:
- Simple CalcSums opportunities instead of manual loops
- Basic SetLoadFields for large datasets
🟡 Medium Complexity (5 procedures per tier) – Business Central-specific knowledge:
- FlowField vs CalcSums decision-making for different scenarios
- N+1 query pattern elimination
- Date range optimization patterns
🔴 Hard Challenges (3 procedures per tier) – Advanced AL architectural knowledge:
- Complex SIFT key optimization for date ranges
- Advanced grouping and sorting algorithms
- Multi-table optimization patterns
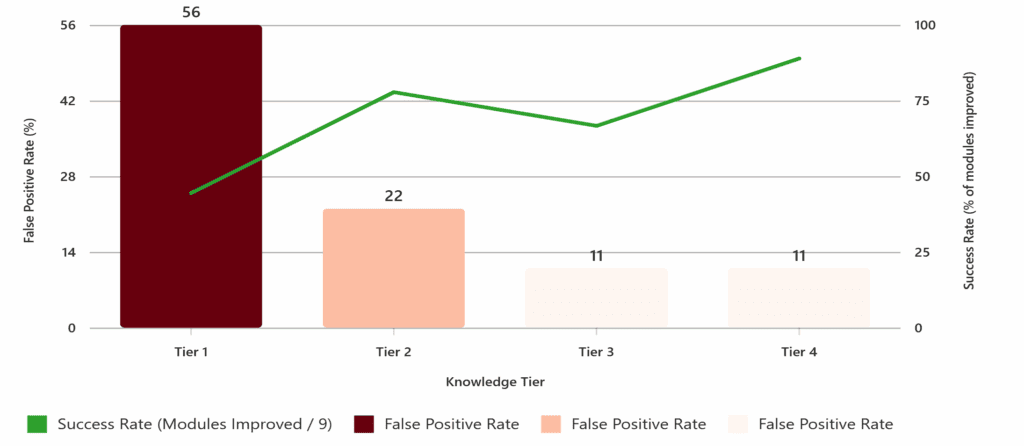
🚫 Red Herrings (10+ procedures per tier) – Already optimal code to test false positive rates. This was crucial – could each tier identify when NOT to optimize?
Dual Measurement System
The framework measured both performance improvements and decision quality:
Performance Toolkit Measurements:
- Execution time (millisecond-level precision)
- Database efficiency (SQL call count, index usage)
- Memory usage patterns
- Network traffic optimization
Optimization Decision Logging:
Every tier automatically logged detailed analysis showing which optimizations were identified, the technical reasoning applied, and confidence levels. This let me see not just whether performance improved, but whether the optimization decisions demonstrated genuine understanding.
Scientific Controls That Made the Difference
Eliminating Variables:
- Identical inefficient code patterns across all tiers
- Shared test dataset through Common-Data-Infrastructure extension
- Only tier-specific
.copilot/folders differed between environments - Standardized optimization prompts via
.vscode/copilot-instructions.md
Answer Key Validation:
Before running any tests, I created a comprehensive checklist system that pre-classified every optimization opportunity by priority and expected outcomes. This wasn’t just documentation – it was a strategic validation framework:
- Priority Classification: Each inefficient pattern was ranked by difficulty (Easy Win, Medium Complexity, Hard Challenge, Red Herring)
- Expected Performance Targets: Specific improvement ranges for each optimization (2x, 10x, 100x+ improvements)
- Knowledge Level Requirements: Which tiers should be capable of identifying each optimization
- False Positive Traps: Already-optimal code that should NOT be modified, testing whether each tier could avoid harmful changes
- Validation Criteria: Concrete measures for determining whether each optimization was correctly identified and properly implemented
This checklist approach meant I could objectively score each tier’s performance against predetermined success criteria rather than making subjective judgments after the fact.
This wasn’t just “let’s see what happens” – it was designed to provide definitive evidence about which knowledge engineering approaches actually work, and which ones are worth the investment.
What I Found (And What Surprised Me)
The results were… not what I expected.
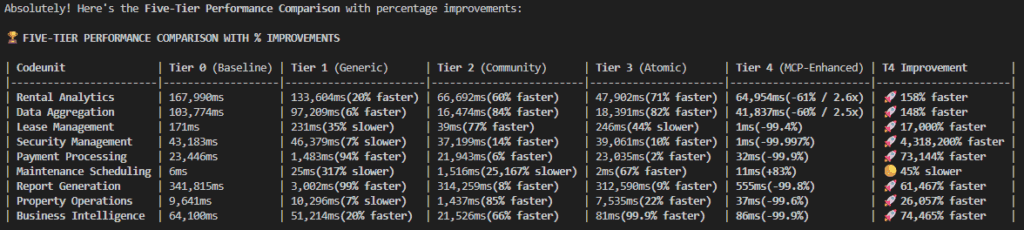
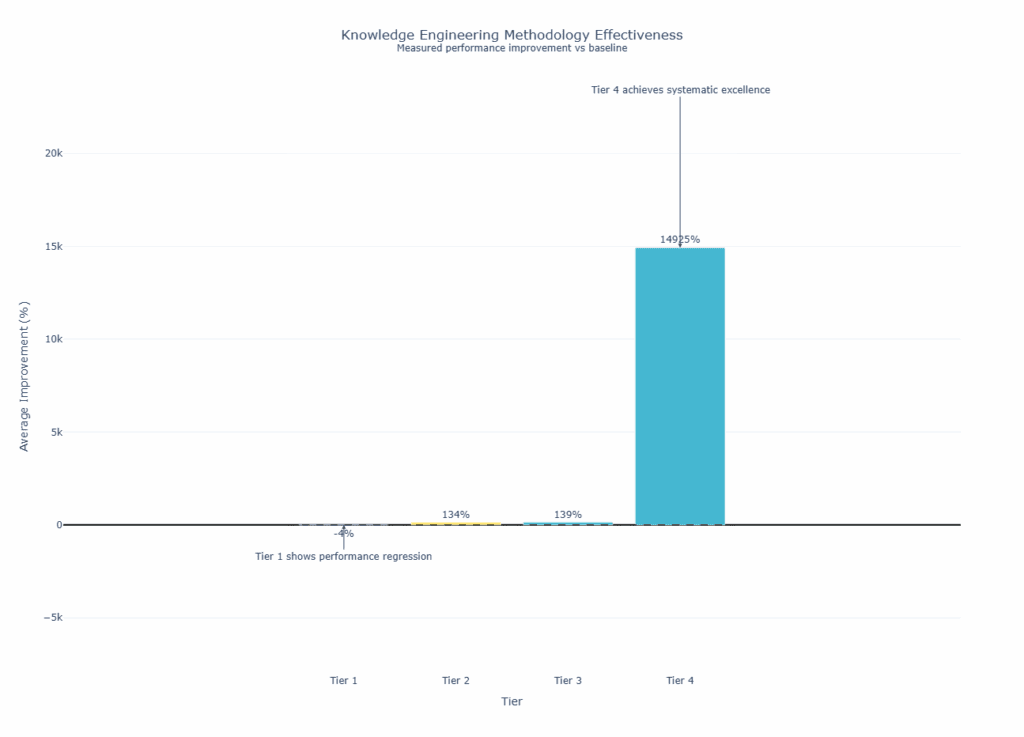
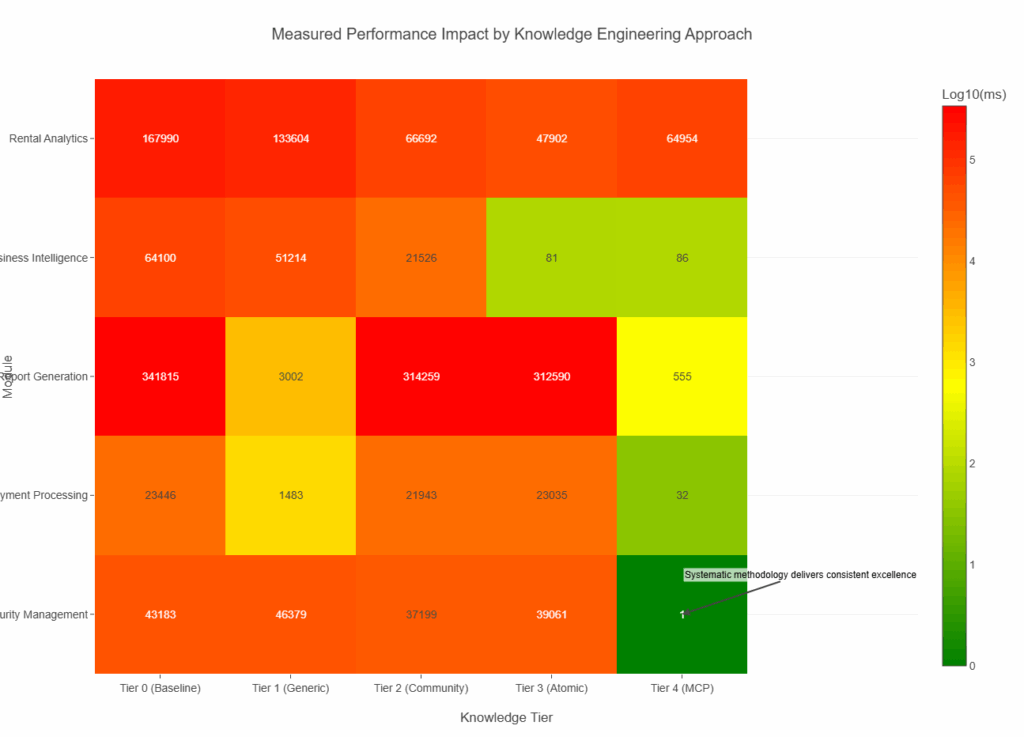
Tier 1 (Generic Programming) was worse than no knowledge at all. About half the optimizations actually hurt performance. Generic programming advice confused GitHub Copilot when applied to Business Central’s specific patterns.
Tier 2 (Community Knowledge) showed modest improvements – typically 50-85% better performance where it worked, but inconsistent quality.
Tier 3 (Atomic Knowledge) had some breakthrough moments. The business intelligence module went from 64 seconds to 81 milliseconds – a 746x improvement. But it was hit-or-miss across different modules.
Tier 4 (MCP-Enhanced) was systematically better. Six out of nine modules achieved 100x+ improvements, with much more consistent quality.
The Part That Actually Matters
The raw performance numbers aren’t the main story here. What surprised me was discovering how much the knowledge delivery approach affects AI decision-making quality.
It’s not just about having more knowledge – it’s about having the right knowledge, structured properly, delivered at the right time.
Generic knowledge created noise that confused optimization decisions. Atomic knowledge engineering worked much better, but required systematic delivery to be consistently effective.
Why This Might Matter Beyond Business Central
I used Business Central as the testing ground because performance improvements are measurable, but the patterns probably apply to other AI knowledge initiatives:
For teams building AI-assisted development tools: Generic coding standards might not help as much as you’d expect. Domain-specific, atomic knowledge could be much more effective.
For organizations investing in AI knowledge systems: The way you structure and deliver knowledge might matter more than the amount of knowledge you provide.
For anyone curating knowledge for AI tools: Less, more focused knowledge delivered systematically might work better than comprehensive documentation dumps.
The Knowledge Engineering Approach That Worked
Based on this testing, here’s what seemed to work consistently:
Atomic Specificity
Instead of “use efficient queries,” provide “use CalcSums instead of manual loops for aggregation operations.” The more specific and contextual, the better.
Context-Aware Delivery
Knowledge needs to arrive at the right moment, in the right context. Static documentation didn’t work as well as dynamic, contextual delivery.
Systematic Coverage
Ad-hoc knowledge gaps hurt effectiveness. The systematic approach in Tier 4 covered edge cases that manual curation missed.
Quality Verification
AI needs to know when NOT to optimize as much as when to optimize. Lower knowledge tiers had high false positive rates on already-optimal code.
Measurable Outcomes
Without performance metrics, I couldn’t have seen which approaches actually worked versus which just felt like they should work.
What I’m Taking Away From This
This experiment convinced me that knowledge engineering is worth the investment, but the approach matters more than I realized.
It’s not about having more knowledge – it’s about having better engineered knowledge.
It’s not about more powerful AI models – it’s about more effective knowledge architecture.
It’s also not about just building a mountain of wisdom and calling it a knowledge base – it’s also about outlining the processes and methodologies that make that knowledge usable and effective.
The organizations that figure out systematic knowledge engineering will probably have an advantage over those still treating it as an afterthought.
What This Means for Your AI Projects
If you’re evaluating AI knowledge initiatives: Consider testing small, controlled experiments before investing heavily in comprehensive knowledge curation.
If you’re already building AI knowledge systems: The structure and delivery method might be more important than the total amount of information.
If you’re seeing inconsistent AI assistance: Knowledge engineering methodology could be the missing piece that makes the difference between AI that helps and AI that gets in the way.
Questions This Raises
This experiment answered some questions but raised others:
- How do these patterns apply to different domains beyond Business Central?
- What’s the optimal balance between knowledge specificity and coverage?
- How can we systematize knowledge engineering to scale effectively?
I’m planning to share more detailed methodology and continue testing these approaches. The goal is to figure out practical, repeatable techniques that actually work.
Ready to Test Your Own Knowledge Engineering?
If this approach interests you, the testing repo is available for anyone who wants to try similar testing in their domain. I’m curious to see if these patterns hold across different technologies and use cases.
The data suggests that knowledge engineering isn’t just important – it might be the difference between AI assistance that helps versus AI assistance that hurts.
Want to explore the detailed methodology? The complete experimental framework, including code and analysis techniques, is available for the community. Because I’d rather see more people succeed with AI knowledge engineering than keep this approach to myself.
JeremyVyska/bc-aiknowledge-test
I’m curious about your experiences with AI knowledge engineering. Have you seen similar patterns in your domain? What approaches have worked best for your team?
Jeremy Vyska is a Microsoft MVP within Business Central, expanding the focus on practical AI optimization and development acceleration techniques. Connect with him on LinkedIn for more insights on AI integration and Business Central development.